로드밸런싱이란?
보통 운영체제의 프로세서의 작업 스케쥴링 또는 네트워크에 주로 사용되는 용어이다. 지금 알아보는것은 네트워크 로드밸런싱을 의미한다. 즉, 서버가 여러개(Sclae-out)일 대 요청 트래픽을 적절하게 분산시켜주는 서비스가 Load balancing이다.

서버 다중화 환경에서의 세션 불일치
단일 서버 환경에서 session을 통한 로그인을 구현할때 session 불일치 문제를 신경쓸 필요가 없다. 하지만 서비스가 커짐에 따라 한대의 서버로 운영하는것이 불가능해졌다고 가정해보자. 그래서 서버를 업그레이드 해야되는데 다음과 같이 두가지 방식이 존재한다. scale- up, scale- out
scale - up
서버 자체 성능을 늘려 부하를 견딜수 있게 하는 방식이지만, 여전히 서버 한 대에 모든 트래픽이 집중되므로 만일에 서버 장애가 생길시 서버가 복구될 때까지 서비스를 중단해야 하는 상황이 발생할 수 있는 위험이 있다.
scale - out
서버를 여러대로 늘려서 각 서버에 로드밸런싱으로 트래픽을 분산하게 한다. 그래서 서버 한대에 장애가 생겨도 다른 서버는 살아 있느니 서비스 문제가 생기지 않는다. 그러나 이때 서비스 이용에 발생하는 커다란 문제점이 있는데 바로 데이터 정합성, 세션 불일치 문제다. 왜냐하면 여러 대의 서버가 각각 세션 저장소를 독립적으로 갖기 때문에 데이터 불일치 문제가 바랭하기 때문이다.
세션의 불일치 해결 방법
1. Sticky Session 방식
간단하게 생각해보면 로드밸런서가 랜덤으로 아무 서버에게 요청을 보내서 발생된 문제이니까, 만약 클랑이언트의 요청이 어느 한 서버에 도달해 세션 데이터가 생겼다면, 앞으로 이 서버는 해당 클라이언트만의 요청/응답만 처리하도록 고정해 주면 된다.

Sticky Session 은 말 그대로 고정된 세션을 의미한다. Stickty는 번역하면 끈적임, 껌딱지 라는 뜻이다. 쉽게 말해서 해당 서버에 껌딱지처럼 붙어있다고 생각하면된다.
다음은 sticky session 방식으로 어떻게 로드 밸런서가 클라이언트와 서버의 연결을 지속시킬수 있는지의 과정이다.

1. 클라이언트는 서버에게 처음 요청을 전달한다. 그러면 로드밸런서는 서버들 중 하나에게 요청을 보내 처리한다.
2. 서버에서 클라이언트에 응답을 보낼 때, Set Cookie : Serverid= 서버1 이런 형태로 정보를 쿠키에 담아 보낸다. 쉽게 말해 너를 담당하는 서버 정보를 클라이언트의 쿠키에 저장하는 것이다.
3. 이후, 클라이언트가 다시 서버에 요청을 보낼때 Cookie : Servierid = 서버1 을 함께 보낸다. 그러면 로드 밸런서가 우선적으로 요청에 쿠키 정보가 있는지 확인하고, 쿠키의 정보를 확인했다면 해당 요청은 해당 쿠키가 생성되어 있는 서버로 보내지게 된다.
4. 만약 존재하지 않는 쿠키라면, 로드 밸런서의 알고리즘에 의해 선정된 다른 서버에 쿠키가 생성되어 다음에 똑같은 요청이 오면 같은 경로로 맵핑시켜 줄 수 있도록 한다.
이렇게 동일한 사용자가 세션이 있는 해당 서버에 계속 요청을 보낼 수 있도록, 지속적으로 서버 정보가 쿠키를 통해 응답에 삽입되어 보내지게 되어, 클라이언트와 서버가 서로 연결을 유지할수 있는 것이다.
Sticky Session 문제점
특정 서버에 트래픽이 집중되는 문제 : 고정된 세션을 사용한다는 말은 사용자가 접속해야 하는 서버가 고정되어 있기 때문에 하나의 서버에 트래픽이 집중될 수 있다는 위험성을 갖고 있다는 말이다.
세션 정보의 유실 : 서비스 중에 만일 하나의 서버에 장애가 발생하게 되면 해당 서버를 사용하는 사용자들은 세션 정보를 모두 잃게 된다. 이렇게 되면 다른 서버에서 세션 인증을 다시 해야 하는 문제가 생기게 된다.
이처럼 Sticky Sesstion에서는 사용자와 세션 정보를 갖고 있는 서버를 1:1로 매핑해주어 세션 불일치를 해결하지만, 문제가 발생하면 Scale Out의 장점인 트래픽 분산과 가용성을 제대로 활용하지 못하게 되는 경우가 발생할 수 있게 된다.
Session Clustering 방식
세션 정보를 각 서버마다 저장하는게 아닌 세션 데이터를 복사해 서버들에게 전파해 가져다 쓸수 있으면 되지않을까?
세션 클러스터링은 서버들을 하나의 클러스터로 묶어 관리하고, 클러스터 내의 서버들이 세션을 공유할 수 있도록 하는 방식이다. 예를 들어 서버1에서 Loing SEssion이 저장되었다면, 서버2와 서버3에도 서버1에 저장되어있는 세션을 전파(복사)하는 것이다.
하지만 Sesstion Clustering도 문제점이 있다.
Sesstion Clustering 문제점
서버 세팅의 어려움 : 이 방식은 scale out 관점에서 새로운 서버가 하나 뜰 때마다 기존에 존재하던 WAS에 새로운 서버의 IP/Port를 입력해서 클러스터링 해줘야 하는 불편함이 있다.
추가 메모리 비용 : 서버마다 동일한 세션 정보를 가지고 있어야 되기 때문에, 서버가 확장 될수록 복제해야 할 세션 데이터가 늘어나고 이는 추가적인 오버헤드로 이어진다. Tomcat를 예로 들었을 때, 모든 데이터를 각각의 Tocmat 노드에게 전달해야 하고 배포하는 노드가 아닐 경우에도 복사를 진행하기 때문에 불필요하게 메모리를 차지된다. 즉, 효율적인 메모리 관리가 이루어지지 않는다.
네트워크 트래픽 증가 : 데이터 변경이 발생할때 마다 세션을 전파(복사)하는 작업이 일어나기 때문에 네트워크 요청 트래픽이 증가하게 된다.
시차로 인한 세션 불일치 발생 : 세션 잔파 작업 중 모든 서버에 세션이 전파되기까지의 시간차로 인한 세션 불일치 문제와 같은 예상치 못한 문제가 발생할 가능성도 있다.
Sesstion Storage 방식
위의 2가지 방식의 단점을 보완하여 다중 서버에서 세션을 공유할 수 있는 방법은 없을까? 모든 서버에 일일히 세션 메모리를 복제/저장하는 것이 낭비라면, 그럼 별도 세션 저장소를 외부에서 생성하고 각 서버들이 가져와 사용하면 되지 않을까?
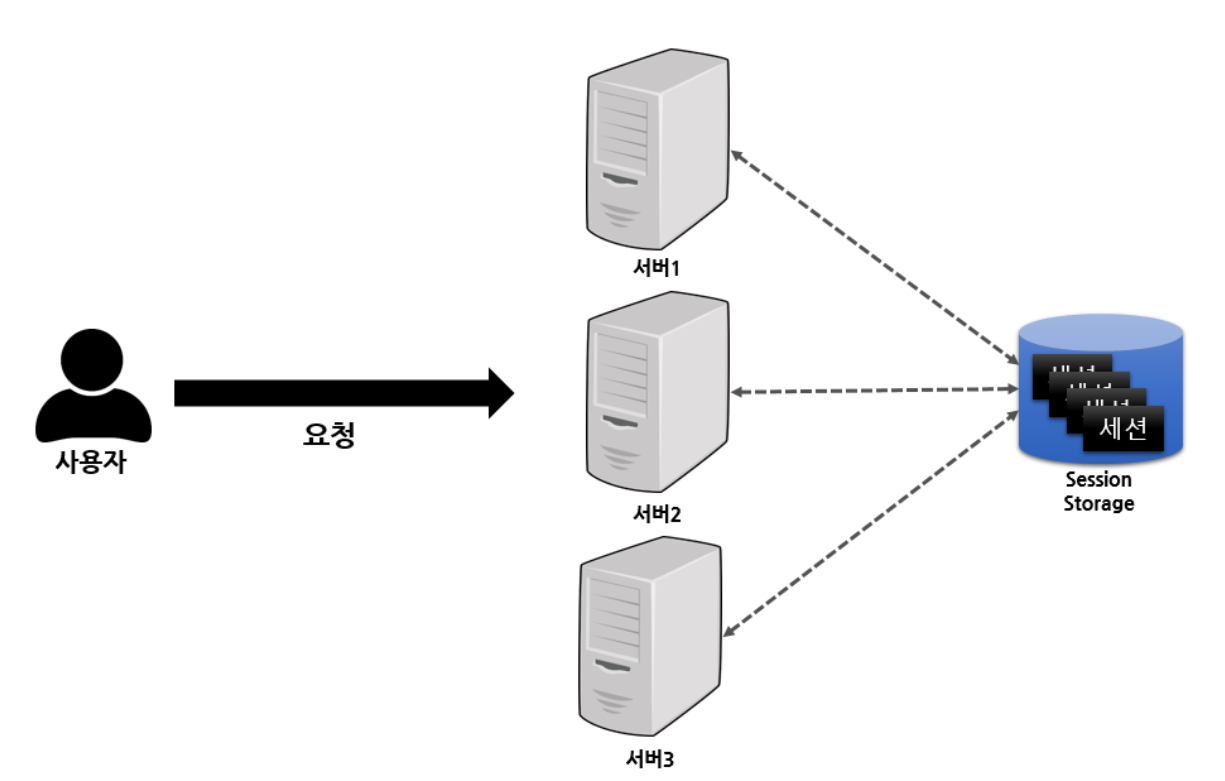
세션 스토리지는 기존의 서버 내 세션 저장소를 이용하지 않고, 로컬 서버에서 분리해 별도의 세션 저장소를 두고 서버들이 이를 공유함으로써 세션 불일치를 해결하는 방식이다.
따라서 새로운 서버를 추가하더라도 추가한 서버에만 세션 저장소 정보를 명시해주기만 하면 되기 때문에 기존 서버의 수정이 발생하지 않는다는 장점이 있게 된다. 그래서 세션을 저장할 때 세션을 복제해 다른 서버들에 보낼 필요가 없어 WAS들끼리 불필요한 네트워크 통신 과정을 진행하지 않아도 되어 성능면에서도 유리하다.
또한, 한 서버에 장애가 발생하더라도 세션은 이와 독립되어 별도로 존재하기 떄문에 세션을 활용한 서비스에 영향을 미치지 않는다.
Session Storage 종류
1. Disk방식으로 되었는 데이터베이스
2. In-Memory 기반의 데이터베이스
Disk Database(MySql, Oracle) : 말 그대로 세션 데이터를 디스크에 저장하는 것이다. 따라서 전원이 공급이 안되도 디스크에는 정보를 잃지 않고 잘 유지하지만, 큰 단점으로는 속도가 너무 느리다는 것이다.
In-Memory (redis/ Memchached) : In-Memory는 데이터를 메모리에 저장하는 방식이다. 그래서 I/O 속도가 디스크와 비교해서 매우 빠르다. 하지만 이것도 단점이 있는데, 전원이 공급되지 않으면 기억하고 있는 데이터를 모두 잃어버린다.
L2 (Data Link Layer)
브릿지, 허브등에서 사용되는 로드밸런싱이다. 네트워크 장비의 고유한 Mac 주소(80-00-20-30-1C-47)를 이용하여 로드밸런싱을 한다. 당연히 스위치는 Mac테이블을 가지고 있어야하며, 이를 기준으로 패킷을 전송한다.
- 스위치 Mac Table에 정보가 있다면 해당 주소로 이동 시킨다
- 만약 Mac Table에 정보가 없다면, 다른 장치에 전부 전송을 해보고, 응답하는 장비를 Mac Table에 등록한다.
L3(Network Layer)
L2에 라우팅기능을 넣은 로드밸런싱이다. 즉, 라우터 기기의 자체 기능을 이용해 IP 주소 (213.12.32.123)를 로드밸런싱한다.
- 라우팅 테이블에 정보가 있다면 해당 IP로 이동 (Forwading) 시킨다.
- 만약 라우팅 테이블에 정보가 없다면, 라우터는 해당 요청을 버린다. (Drop)
- 즉, Public IP가 아닌 내부망에서만 사용하는 Private IP는 해당 테이블 정보가 없으면 네트워크 통신이 불가능하다.
- 라우터는 라우팅 프로토콜을 활용하여, 어떠한 대역으로 패킷을 보내는게 오류없이 갈 수 있는 경로인지 학습한다.
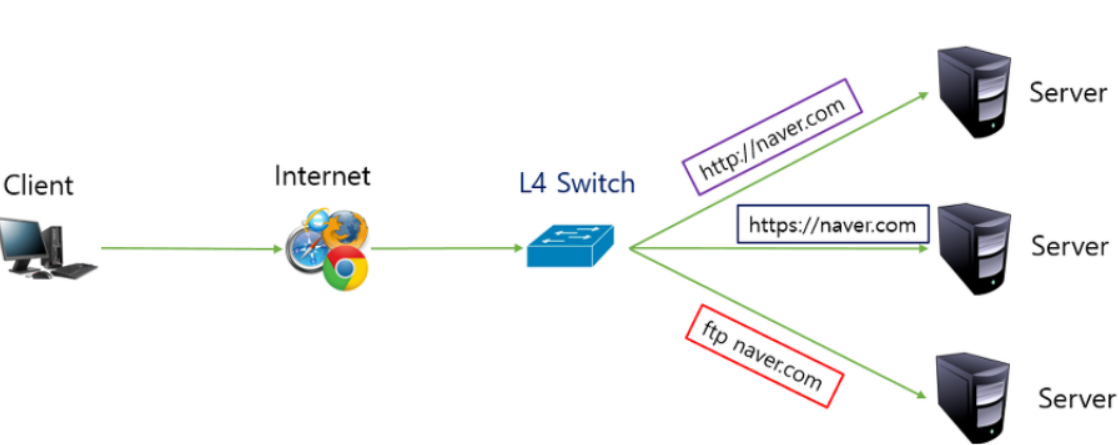
L4(Transport Layer)
IP + Port 를 이용한 로드밸런싱이다. 단순 라우터만 아니라, TCP/IP 프로토콜을 사용한다. 주로 round Robin 방식을 이용한다.
Port 구분이 가능하기에 프로토콜(HTTP, FTP)마다 다른 서버로 보내도록 설정이 가능하다.
실제 IP들을 하나의 가상 IP(Virtual IP, VIP) 로 묶어서 처리할 수 있다.
- VIP를 통해 요청 받은 작업을 여러개의 서버로 분산시킬 수 있음
- VIP를 통해 연결된 서버가 다우되어도 자동으로 다른 서버가 해당역할을 하도록 전환하는 Failover 기능지원
L7 Switch (Application Layer)
어플리케이션 영역, 즉 HTTPRequest 요청 내용까지 판단하여 로드밸런싱 한다.
L4가 사용하는 IP _ Port 뿐만 아니라 URI정보, 쿠키등을 다 판단해 유연하게 네트워크 밸런싱을 할 수 있다.
ex) L4 Switch에서 제공하는 기능을 다 포함한다. 프로토콜(port)별로 다른 서버에 할당 가능하다.
ex) www.naver.com/blog 와 www.naver.com/cafe 를 다른 서버가 처리하도록 설정할 수 있다.
ex) URI, 쿠키, 바이러스 패턴등을 분석해 특정 트래픽을 받지 않도록 필터링 할 수 있다.
ex) 패킷의 데이터부분, Payload를 분석하여 DDOS 같은 서비스 공격을 완화 할 수 있다.
회사에서 공유기(사설 IP)를 사용하는 경우 -> 한 회사의 모든 요청 IP가 똑같다.
- L4 스위치는 모든 요청을 한 서버에 할당한다. IP+Port가 같으니깐...
- L7 스위치는 IP+Port 뿐만 아니라 HTTP Request를 이용해 분산시키므로, 적절하게 분산 가능하다.
하지만 L4에 비해 분석해야할 정보가 많아 로드밸런싱 작업이 어렵고 무거워진다. 그래서 성능 좋은 L7 Switch 장비의 가격이 매우 비싸다.
L4 와 L7 공통점, 차이점
공통점
- 들어온 packet을 적절한 목적지로 전달(스위치) 역할 수행한다.
- 적절한 알고리즘을 통해 로드밸런서로서의 역할을 수행한다.
- 스위치 및 서버별 Health Check를 통해, 이중화 구성후 장애시 Standby 상태의 기기는 장애스위치의 패킷을 넘겨와 active로 동작해 서버에 넘겨준다.
차이점
- L4는 로드밸런서에서 알고리즘을 통해 server1 또는 server2로 데이터를 전송할지 결정을 하고 Client와 3way handahke를 실시하여 하나의 TCP세션을 갖게 된다. 그 후 application 층에서 클라이언트의 요청정보(HTTP, FTP)를 전달받는다
- L7는 L/B에서 콘텐츠 기반 스위칭을 위해 3way ahndshake를 보류한다. L/B와 client 간 3 way handshake를 실시하여 따로 TCP 세션을 형성, L7과 server서버는 또 다른 TCp 세션을 형성하고 데이터를 중계한다.
- L7패킷 분석을 통한 바이러스 감염 패킷 필터링이 가능하다.
- L7은 L4의 서비스 단위 로드밸런싱을 극복하기 위한 포트 + 페이로드 패턴을 이용하여 패킷스위치을 한다.
- L4는 TCP/UDP 패킷 정보를 분석하고 해당 패킷이 사용하는 서비스 종류별(HTTP, FTP 등)로 처리하기 때문에 프록시 문제가 발생 될 수 있다.
총 정리
------------------------------------------------------------------------------------------------
L7 스위치
로드밸런서라고도 하며, 서버의 부하를 분산하는 기기 ( URL, 캐시, 쿠키들을 기반으로 트래픽 분산)
L7과 L4의 차이점
L4 : 전송계층을 처리하는 기기로, 스트리밍 관련 서비스에서는 사용할 수 없고, 메시지를 기반으로 인식하지 못하고 IP와 PORT를 기반으로 트래픽을 분산
L7 : IP와 PORT 이외에도 URL, 헤더, 쿠키 등을 기반으로 트래픽을 분산
헬스 체크란?
L4 스위치, L7 스위치 모두 헬스체크를 통해 정상적인 서버 또는 비정상적인 서버를 판별한다.
-> 서버에 부하가 되지 않을 만큼 요청 회수가 적절해야한다.
로드밸러서를 통한 서버 이중화?
로드밸러서는 2개 이상의 서버의 기반으로 VIP(가상 IP)를 제공하고, 사용자는 이 가상 IP로 접근 로드밸런서 뒷단에 서버 2개가 있다고 가정하고, 서버 1개가 장애가 발생해도, 나머지 한대의 서버에 트래픽을 보낼 수 있다.
인터넷 계층을 처리하는 기기
라우터(L3 스위치) 이며 네트워크를 연결, 분할, 구분시켜주는 역할을 한다. 다른 네트워크에 존재하는 장치들끼리 데이터를 주고 받을떄 패킷 소모를 최소화하고 경로를 최적화하여 최소 경로롤 패키을 포워한다.
데이터 링크 계층을 처리하는 기기
블릿지(L2 스위치) 이며 장치들의 MAC를 MAC 주소 테이블을 통해 관리하며, 연결된 장치로부터 패킷이 왔을 때 패킷 전송을 담당 ( LAN + LAN 을 연결시켜주는게 브릿지
물리 계층을 처리하는 기기
NIC, 리피터
NIC : LAN 카드라고 하는 네트워크 인터페이스 카드 (NIC)는 2대 이상의 컴퓨터 네트워크를 구성하는데 사용
리피터 : 약해진 신호 정도를 증폭하여 다른 쪽으로 전달하는 장치
참고 자료
https://vaert.tistory.com/189
https://www.youtube.com/watch?v=9_6COPOMZvI
https://joyhong-91.tistory.com/37